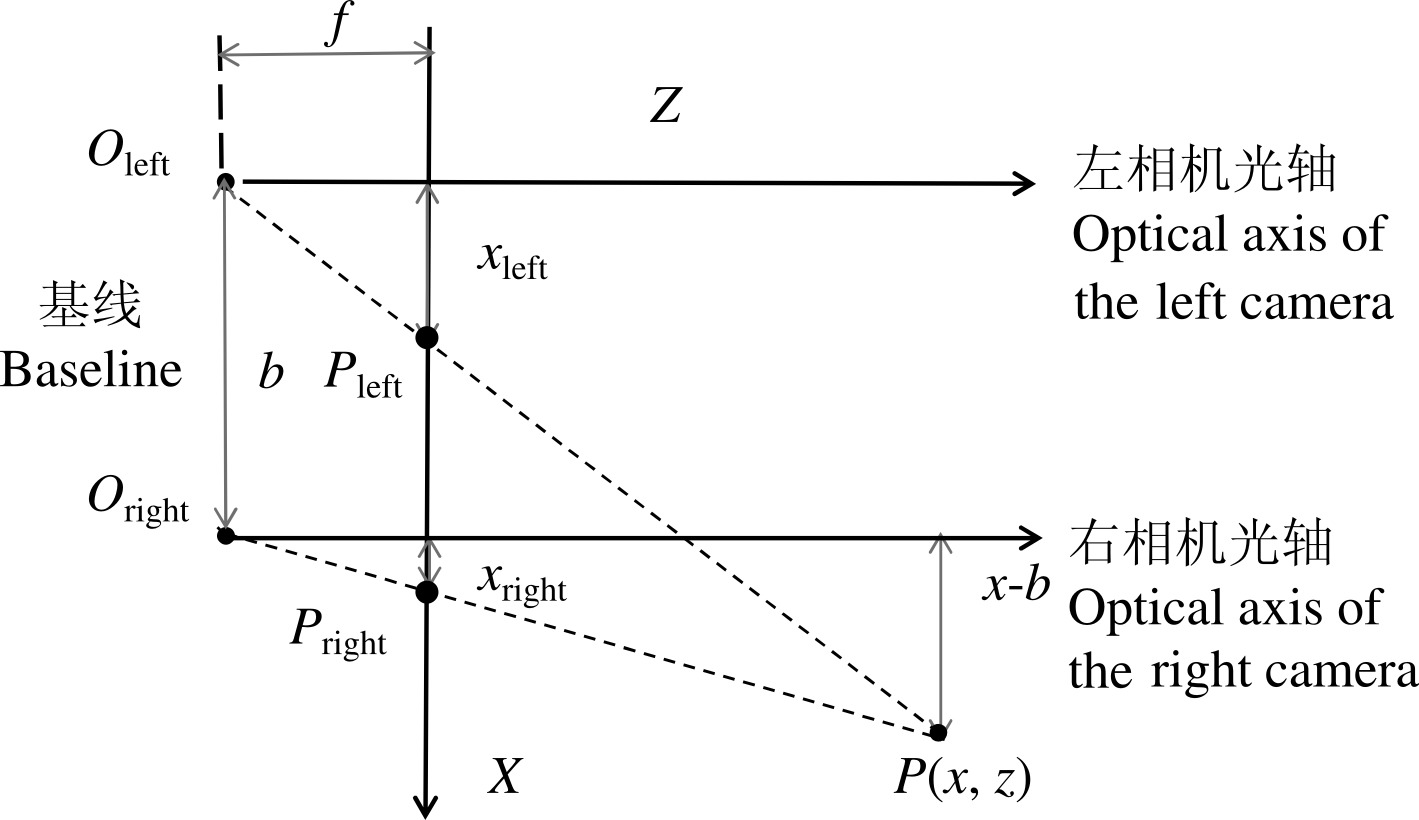
Fig. 7 Schematic diagram of the disparity calculation The figure uses two directional axes, Z and X; Oleft and Oright are the left and right camera optical centers, respectively; P is the positioning point on the object to be measured; Pleft and Pright are the imaging points of the positioning point P on the left and right camera optical sensors, respectively; xleft and xright are the distances of Pleft and Pright from the optical axis of the left and right cameras, respectively; f is the camera focal length; b is the distance between the centers of the two cameras; x is the coordinate of point P on the X-axis; Baseline is the line connecting the optical centers of the left and right cameras.
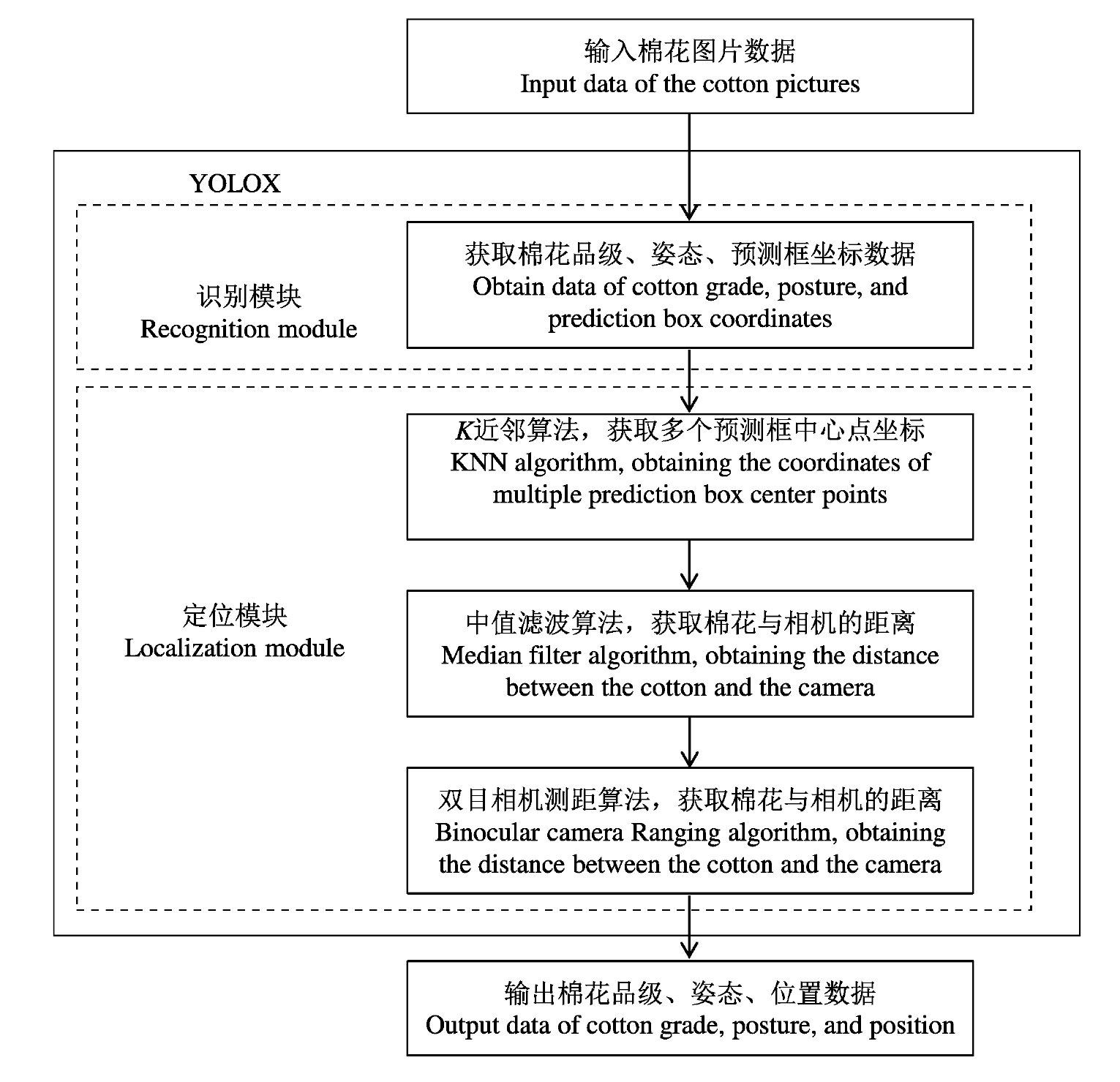
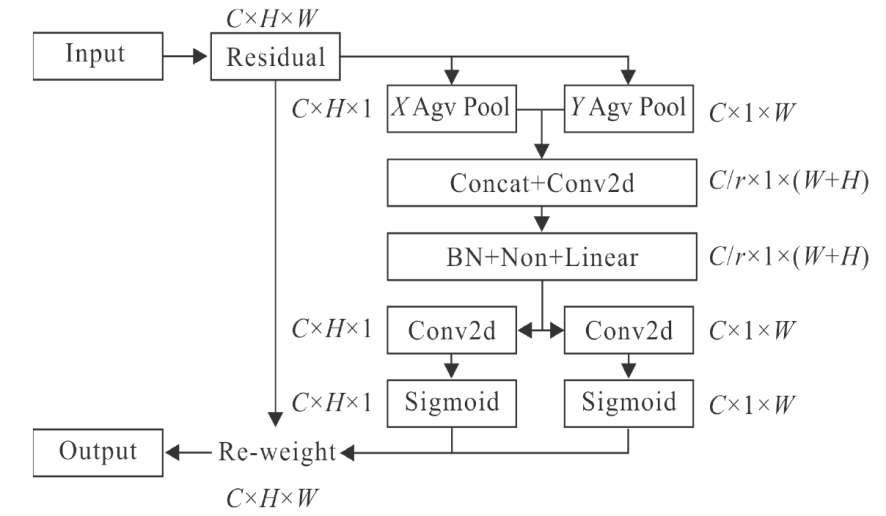
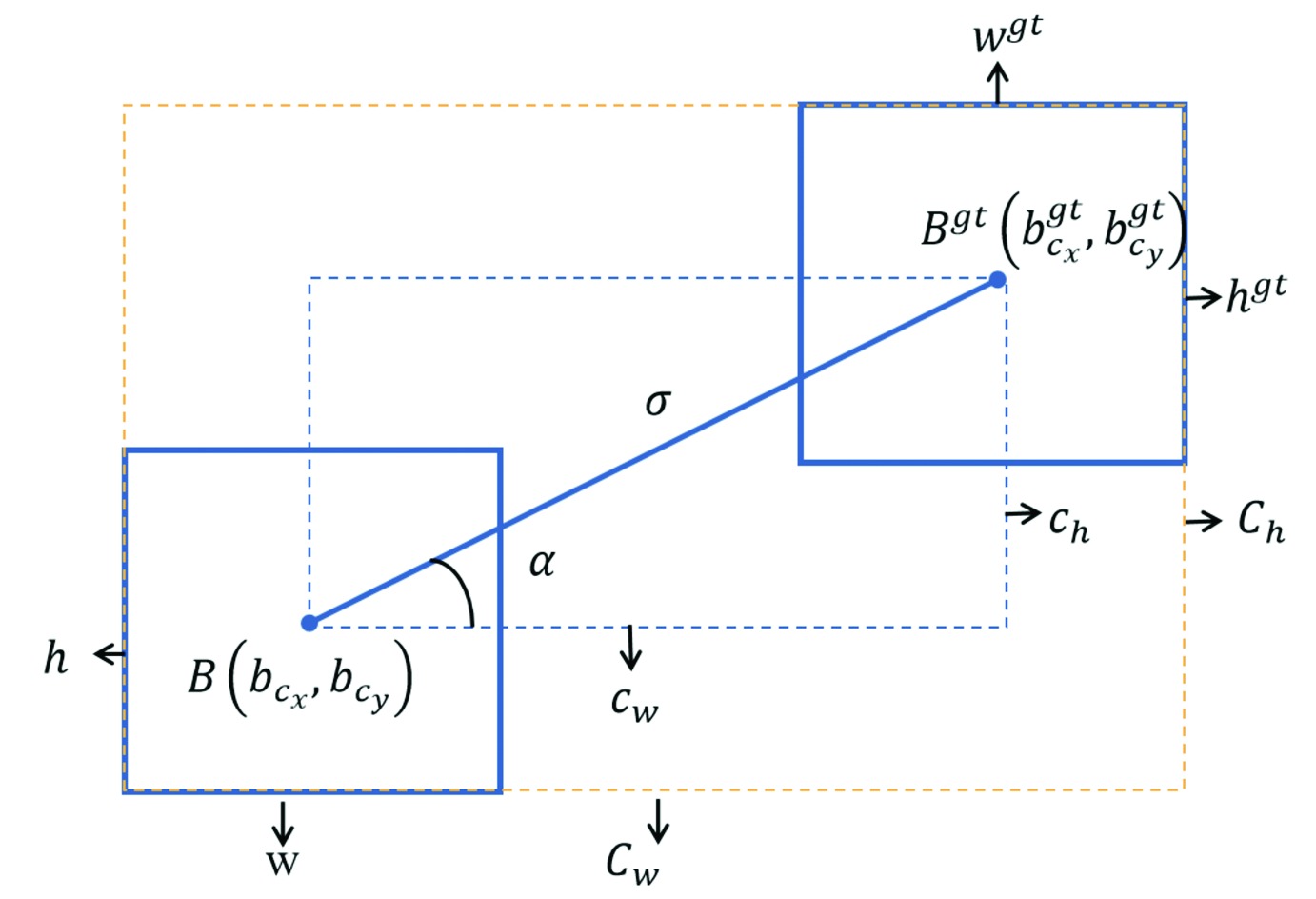
Other figure/table from this article